From pipeline to production: what changed in my photography automation workflow
This post is a continuation of my automation series on amir2000.nl.
The first posts covered the original pipeline, then the major update, then Multi Set and staging, and then release hygiene and review stability.
Now the workflow moved into a stronger production shape with better metadata quality, clearer runtime visibility, and safer review actions.
If you are new to this series, this is part of Photography Tools, where I document real workflow changes, not theory.
Multi Set is now the practical starting point
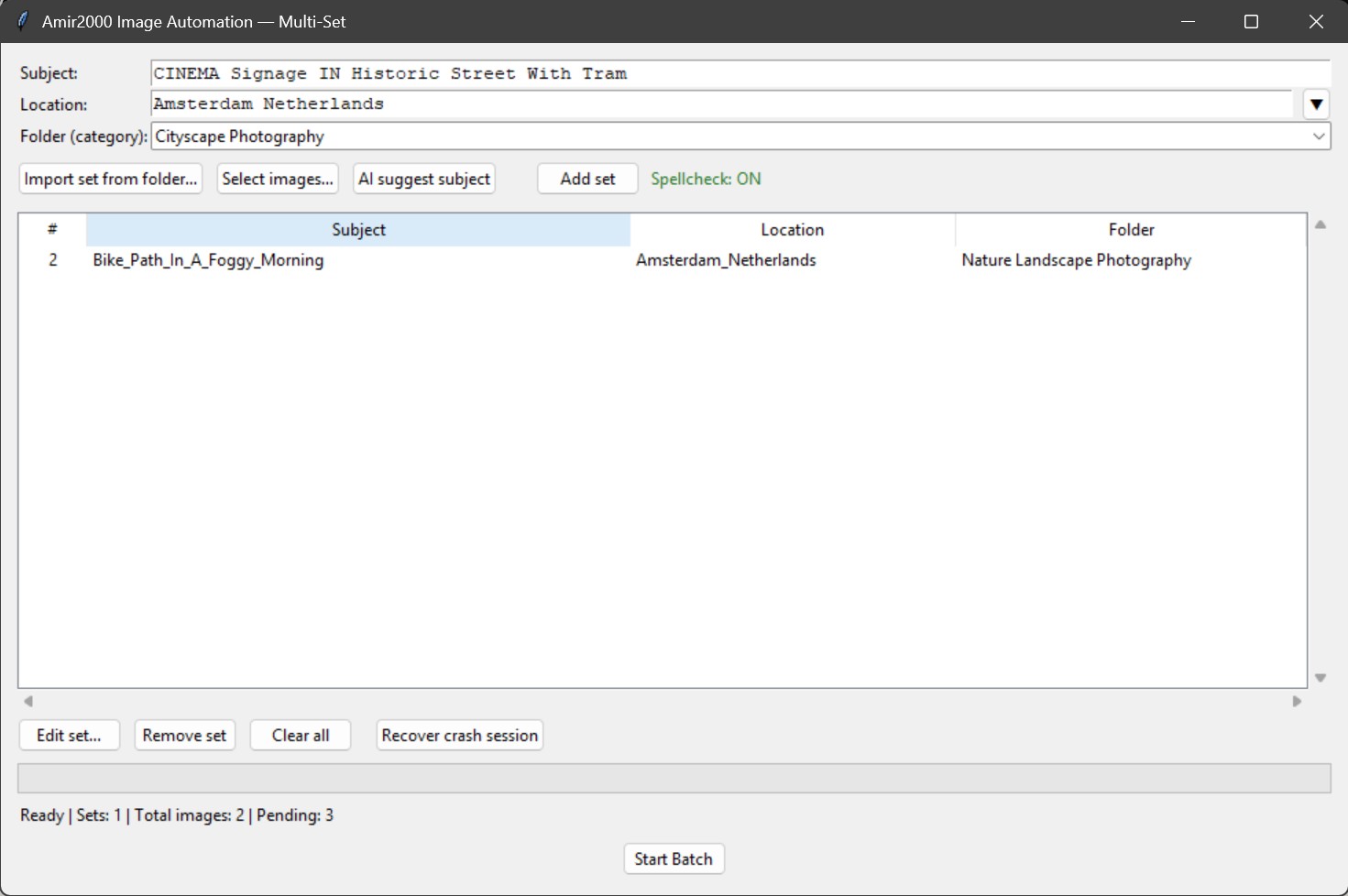
The Multi Set launcher is now the normal entry point for batch runs.
I can prepare multiple sets in one pass, each with subject, location, and category, then launch once and let the queue run through validation, ingest, scoring, and prefill.
What matters in daily work is not only speed, it is continuity.
This layout reduced context switching because I no longer jump between small one-off runs for each subject group.
The queue view also makes mistakes easier to spot before processing starts, which means fewer corrections later in the review editor.
Ollama runtime is visible before processing starts

One important change is startup transparency for the local caption model runtime.
At launch, the console now prints an Ollama startup check that shows model, processor mode, context, and VRAM state.
That means I can immediately see whether a run is on GPU or CPU before the heavy stages begin.
In earlier iterations, this required manual checking after the run started, which cost time and introduced guesswork.
Now it is visible up front, and that single line makes troubleshooting much faster when machine state changes.
Review editor now supports safe regenerate on bad rows
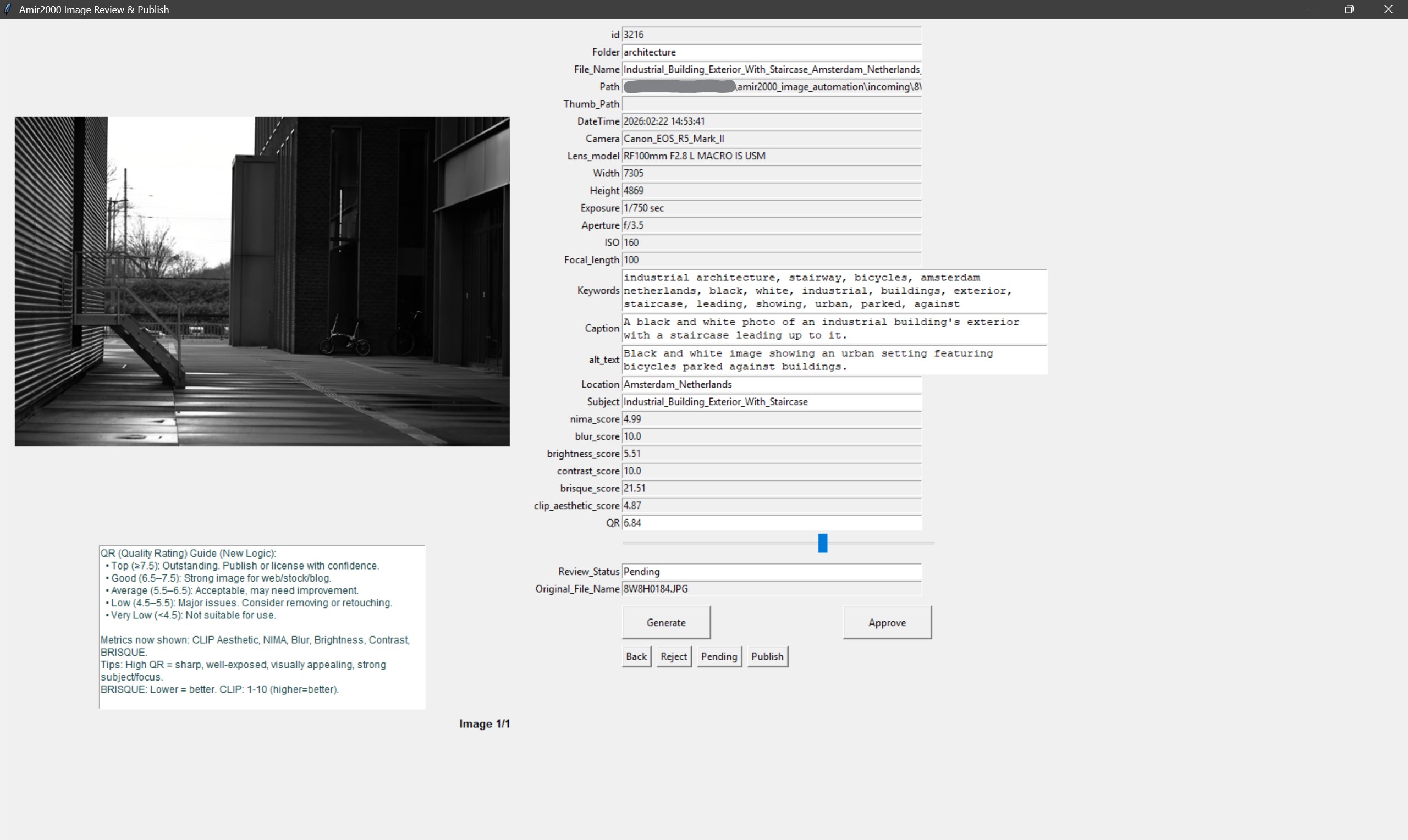
The review editor now includes a dedicated Generate action for the active row.
This lets me retry caption, alt text, and keywords directly in review without rerunning the full batch.
The important part is safety, not only convenience.
Regeneration now guards against duplicate captions in pending rows, so a retry does not silently clone metadata across different images.
That fits the review-first rule of this project: AI can propose, but final quality and publish decisions stay under manual control.
This is a direct improvement over the previous flow where fixing one weak row often required broader reruns or manual rewriting.
Classifier hints improved subject and metadata quality
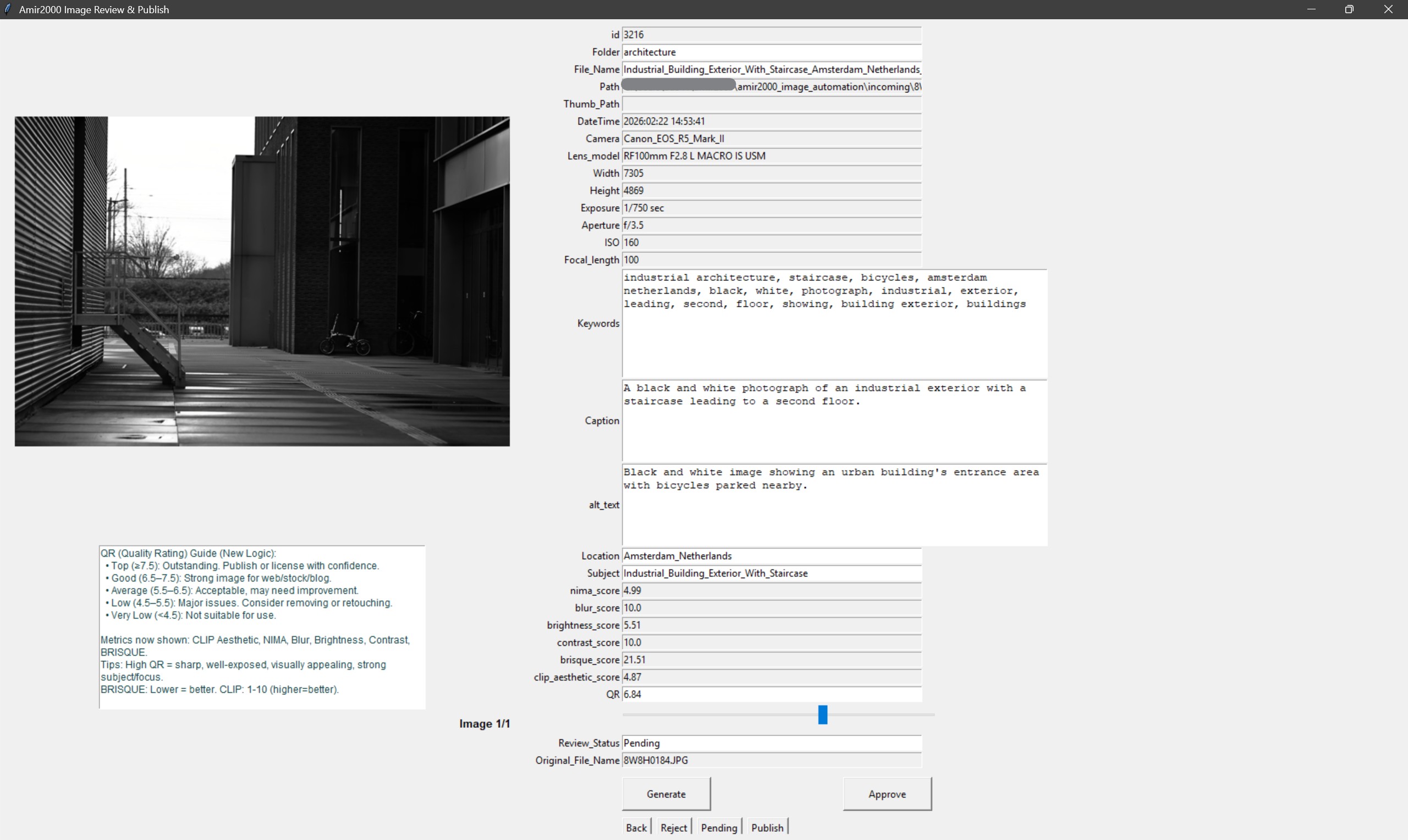
A stronger local classifier path is now integrated into subject suggestion and metadata generation, especially for nature-oriented content.
In practice, this improves consistency between filename context, subject labels, and generated text fields.
It does not replace review, but it gives better first-pass suggestions and reduces weak generic phrasing.
For me, this means fewer corrective edits per row and cleaner metadata output when moving from pending to approved.
The result is a smoother handoff from automated draft to publish-ready record.
Prefill QC is now explicit before editor handoff
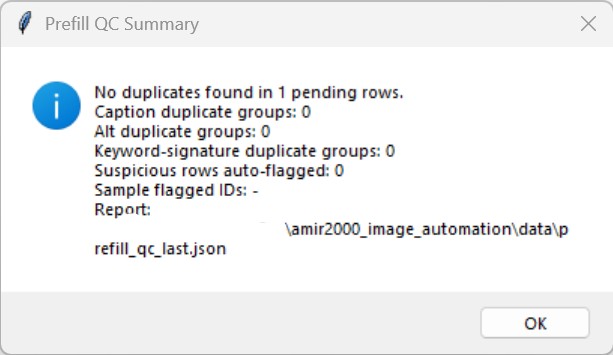
Another production-level change is a clearer prefill quality checkpoint before the review editor opens.
The run now reports duplicate checks and suspicious text flags in a dedicated QC summary, with an artifact report saved for traceability.
This gives an immediate signal when generated text needs attention, instead of discovering issues only during final approval clicks.
The workflow is still practical for small batches, but this QC layer becomes more important as volume grows because weak rows are surfaced early.
Failure paths stay recoverable, with clean rollback behavior
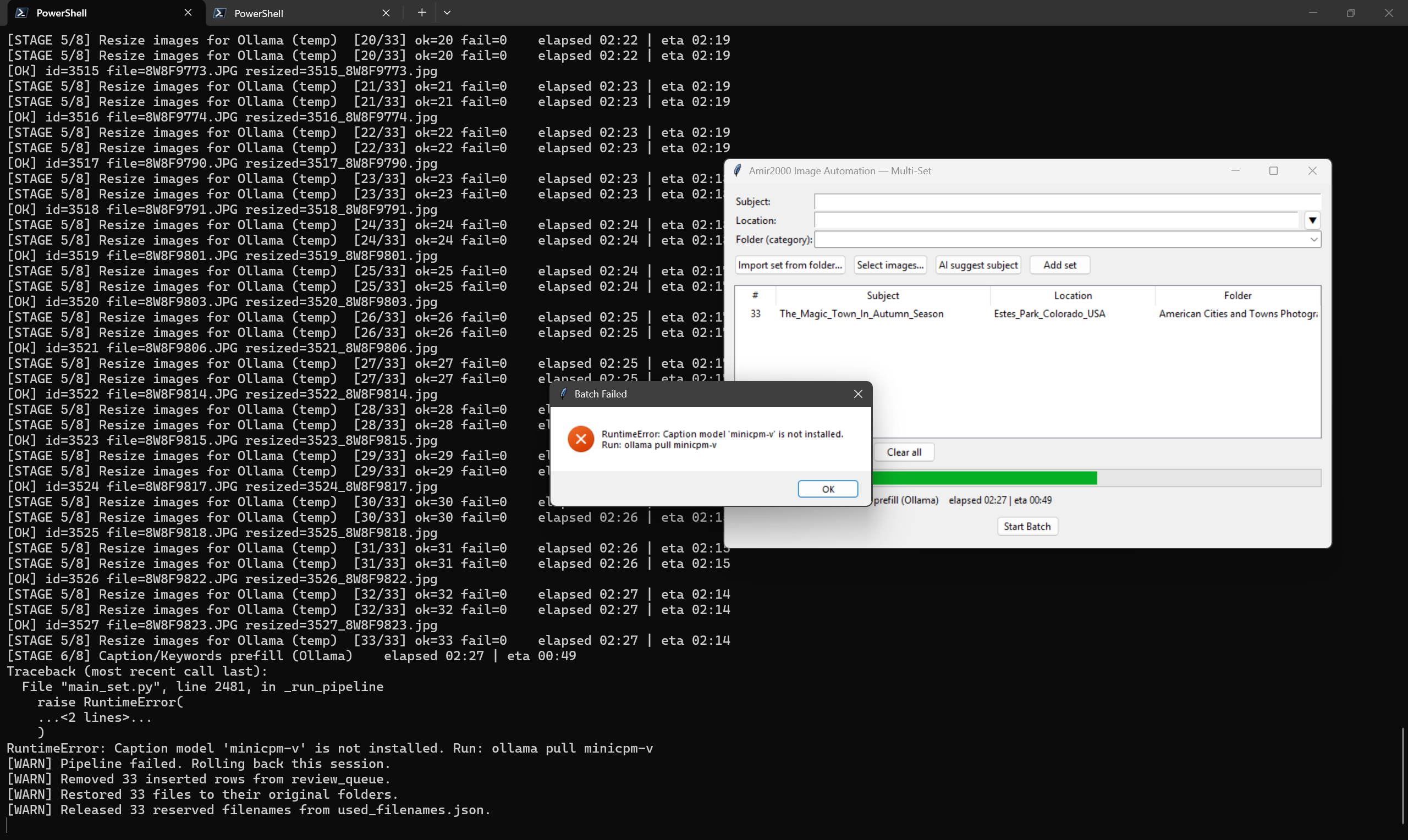
Reliability is not only about success paths.
When a stage fails, the workflow now makes the decision path explicit with retry and rollback behavior that protects queue consistency.
This keeps the process predictable under real conditions, where model startup or environment states can vary between runs.
The goal is not to hide failures, it is to make them readable and recoverable without damaging the next run.
Where the full documentation now lives
This post is the short continuation update.
The full technical documentation is now centralized on amir2000.com, including workflow, runbook, troubleshooting, database model, diagrams, and design notes.
Start here:
Case study overview
Complete documentation index
For prior milestone context on amir2000.nl, see:
From folder to gallery in one flow and
staging, review, and clean releases.
Amir
Photographer, Builder, Dreamer
amir2000.nl
Comments
No comments yet. Be the first to comment!